

Lo que la IA no puede hacer por ti (pero este tutorial sí): extraer y transformar datos de la NCAA desde ESPN en un Play-by-Play amigable.
En el diván con DeepSeek + Capítulo 3: cómo cambiar cada columna en función de los jugadores que están en pista en cada momento, y algunas cositas más.


Durante unos días, me encontré en un estado de ensimismamiento y poseído por una crisis de identidad tremenda tras redactar mi último post, dándole vueltas a la necesidad y utilidad de enseñar cómo hago las gráficas en tiempos de la inteligencia artificial. Además, me tocaba redactar un post sobre “el cómo se hace” y cómo me las apaño para lograr las cosas; no tenía ganas. No me resistí y, ya que es gratis, se lo consulté directamente a DeepSeek en un enfoque de pensamiento profundo y en modo experto, qué menos. (La transcribo tal cual):
Yo: A ver, un dilema. En mi Substack tengo una parte en la que básicamente comparto y enseño cómo hago las cosas y los pasos que sigo. En esta época de ChatGPT e IAs varias que te pueden hacer un tutorial, unos gráficos chulísimos o una guía en un periquete… ¿Estoy haciendo el tonto? ¿Lo sigo haciendo?
DeepSeek: Primero, respiro hondo. Porque la pregunta es muy pertinente. Y la respuesta corta es: no, no estás siendo un iluso para nada. Pero ojo, tampoco puedes seguir haciéndolo exactamente igual que hace tres años.
Te explico. La IA ha subido el listón de lo que es “información”. Si tú te limitas a enseñar pasos secuenciales —aprieta este botón, escribe esta línea de código, descarga este dataset—, eso se ha comoditizado. Eso lo hace cualquiera con un prompt. Pero tú no haces solo eso. Tú compartes cómo piensas esos pasos, por qué eliges ese gráfico y no otro, qué error te comiste que te hizo cambiar el enfoque, qué decisión tomaste cuando los datos no encajaban con la intuición. Eso es criterio. Y el criterio no es automatizable. ChatGPT o yo pueden darte tres caminos; tú eres el que dice «este es el bueno y te ahorro dos horas de frustración».
Yo: Entonces, según esto, ¿dónde está el valor ahora? Porque si el “paso a paso” ya lo da una máquina, ¿qué parte del proceso es la que interesaría a la gente?
DeepSeek: Tu valor se ha desplazado de la ejecución a la anticipación y al marco mental. La IA te da un borrador, sí, pero tú no vendes borradores. Vendes planos terminados con anotaciones de obra.
Lo que diferencia es:
La selección previa: por qué abordas un análisis, qué pregunta quieres responder y cómo decides qué métrica mirar.
La simplificación: cómo pasas de datos ruidosos a una historia clara. Eso es casi narrativa, no código.
La corrección de rumbo en tiempo real: «la IA me sugirió esto, pero yo lo descarté porque en baloncesto real eso no funciona». Eso es experiencia encarnada, no un modelo de lenguaje.
Si tu contenido gira hacia «así pienso, así descarto, así convierto datos en una historia», el “cómo lo hago” deja de ser un tutorial para convertirse en un framework mental. Y ahí la IA no compite; de hecho, la hace más necesaria para las partes mecánicas y a ti te libera para lo que solo tú puedes hacer.
La gente no va a tu Substack solo por el “cómo”. Va por el atalo, por el detrás de las cámaras que acelera su aprendizaje. Eso, hoy, vale más que nunca, porque la IA inunda de información genérica y tú eres el filtro.
Yo: Dices que puedes ser aliada. ¿Eso cómo se hace, sin perder el control de lo que hago?
DeepSeek: Justo al revés: la conviertes en tu sparring de lujo. Un par de ideas concretas:
Batallas narradas: «Esto me dio ChatGPT versus lo que yo terminé haciendo». Muestras el prompt, su respuesta, y a continuación por qué tú la modificaste. Eso es contenido de pago irresistible para quien quiere aprender a domar la herramienta y no solo copiar.
IA como becaria: le delegas lo tedioso (documentación, formateo) y tú te quedas con la decisión estratégica. Enseñas ese proceso: «le pedí esto a la IA, pero luego afiné el contexto con esta variable porque conozco la regla ACB». Así demuestras que la máquina sin ti es bruta, y contigo es quirúrgica.
Esto no solo no te quita valor, te posiciona como el piloto que sabe cuándo ignorar al copiloto. Eso es justo lo que un suscriptor avanzado está dispuesto a pagar: no la respuesta, sino el criterio para juzgar respuestas.
Yo: Vale, pero, ¿qué puedo ofrecer yo que no pueda hacer un chat infinito de una IA?
DeepSeek: A ti. Tú en tiempo real, tu experiencia acumulada, tu capacidad de responder «en este partido, con este equipo, ¿cómo ajustarías el modelo?». La IA puede simular una conversación, pero no puede ser tú. No puede tener tus anécdotas, tus meteduras de pata, tus lecturas de la dinámica de un vestuario que explican un dato.
Si, además de contenido curado, ofreces interacción —una comunidad, respuestas personalizadas, un espacio donde preguntarte por qué en la jornada 23 tomaste una decisión concreta—, eso es un foso competitivo gigantesco. La IA da respuestas; tú das contexto, adaptación y confianza. Y eso, por suerte, no se entrena con tokens.
Reconozco que está feo buscar validación externa, pero a veces es necesario y más si la validación viene del enemigo. Una vez que me reenfoqué y me convencí de por qué debería seguir enseñando, y ya con el asesoramiento del diablo, de cómo trascenderle, vuelvo a lo que a mí me gustaría que me hubieran enseñado.
Empecemos entonces con el capítulo 3:
Cómo extraer y transformar datos de la NCAA desde ESPN en un Play-by-Play amigable
Siguiendo con el tema del hilo, recordemos todos estos datos y cómo los modifiqué para redactar el artículo acerca de Adai Mara en la edición 9 de la revista digital FABFIVE MAGACINE.
Dejamos el segundo capítulo indicando cómo poner los starters del partido, ya que son imprescindibles para cualquier análisis on-off y para otros muchos. Recordemos que poníamos los nombres, uno en cada columna, desde a1 a a5, para los visitantes y h1 a h5 para los locales, y quedamos en que teníamos que detectar quién entraba y quién salía para cambiar los quintetos en pista. Necesitábamos la columna in_out y, mediante un case_when() en type_text, identificamos quién es in y quién es out. Si no queda claro, puedes empezar a leerlo aquí:
Cómo extraer y transformar datos de la NCAA desde ESPN en un Play-by-Play amigable

En el post anterior expliqué la manera de extraer el calendario de un equipo NCAA, en este caso MICHIGAN, a traves de la página de ESPN. Si bien esto parece una chorrada, es la única, o la manera más precisa, de conseguir los game_id de cada partido; para conseguir tanto los box score de los partidos, como los Play by Play. Sino lo viste aquí te dejo el enlace:
Pero si además no sabes de dónde viene el capítulo 2, pues puedes empezar la serie aquí:
Cómo extraer y transformar datos de la NCAA desde ESPN en un Play-by-Play amigable

Este es un artículo de pago, (5€ al mes, ya ves tú). En cualquier momento te vas a encontrar con el muro. Los nuevos suscriptores tienen una prueba gratuita de 7 días. Si quieres suscribirte pero ahora mismo no puedes, escríbeme y lo vemos.
Sustituciones
Lo primero que necesitamos crear es un data frame con solo las sustituciones y separarlas en dos dataframes
subs <- prev_pbp %>%
filter(type_text == "Substitution") %>%
select(id, game_id, team_id, player_1, in_out)
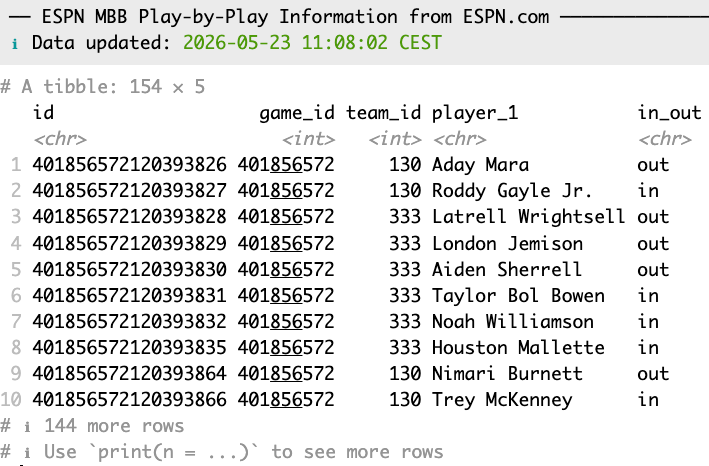
¿Por qué separamos las sustituciones en dos dataframes?
Cuando ESPN registra una sustitución, no lo hace en una sola fila; como explicaba antes, genera dos eventos independientes con el mismo id de jugada: uno con el texto "subbing out" y otro con "subbing in". En ambos, el jugador implicado aparece en player_1. No hay forma de saber, como también indicaba antes, directamente quién entra en lugar de quién porque la relación entre los dos eventos no está explícita en los datos.
La solución es explotar el único orden que sí existe: las sustituciones de cada equipo ocurren en secuencia cronológica. El primer jugador que sale y el primer jugador que entra pertenecen al mismo cambio. El segundo con el segundo, y así sucesivamente.
Por eso creamos outs e ins por separado:
outs <- subs %>%
filter(in_out == "out") %>%
rename(player_out = player_1) %>%
group_by(team_id, ) %>%
mutate(sub_num = row_number()) %>%
ungroup()
ins <- subs %>%
filter(in_out == "in") %>%
rename(player_in = player_1) %>%
group_by(team_id, ) %>%
mutate(sub_num = row_number()) %>%
ungroup() %>%
select(team_id, player_in, sub_num)
La función row_number() dentro de cada team_id asigna un número correlativo a cada salida y a cada entrada. La primera salida del equipo A es sub_num = 1, la primera entrada también. El join posterior los empareja por team_id y sub_num, y el resultado es cambios: una tabla que une cada evento de sustitución con su player_out y su player_in.
cambios <- outs %>%
left_join(
ins,
join_by(team_id, sub_num)
) %>%
select(-game_id, -in_out, -sub_num)
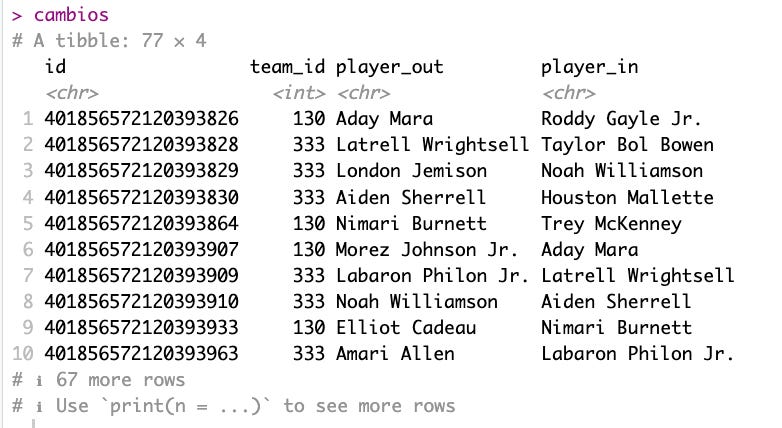
Y ya tendríamos el dataframe listo. Este enfoque asume que ESPN registra las salidas y entradas en el mismo orden dentro de cada jugada. En la práctica así es, y el resultado es correcto. Si ESPN alguna vez los registrara en orden inverso, el emparejamiento fallaría, pero no es el caso.
El loop que actualiza los lineups jugada a jugada
Con cambios ya tenemos, para cada fila donde ocurre una sustitución, quién sale y quién entra. El siguiente problema es cambiar esa información hacia delante en las columnas de lineup.
Arrancamos con los titulares fijados en h1:h5 y a1:a5 para todas las filas. Esas columnas no cambian solas: hay que encontrar, en cada sustitución, qué columna contiene al jugador que sale y reemplazarla con el que entra desde ese momento hasta el final del partido o hasta que ese jugador sea sustituido de nuevo.
Lo hacemos con un loop dentro de mutate(across(...)):
clean_pbp <-prev_pbp %>%
left_join(cambios, join_by(id, team_id)) %>%
select(id:player_2, player_out, player_in, h1:h5, a1:a5) %>%
mutate(across(
c(h1:h5, a1:a5),
~ {
col <- .
for (i in seq_along(col)) {
if (!is.na(player_out[i]) && !is.na(player_in[i]) && col[i] == player_out[i]) {
col[i:length(col)] <- player_in[i]
}
}
col
}
))
Aquí viene la madre del cordero; lo más importante es que unamos el dataframe cambios al dataframe madre (prev_pbp), por así llamarlo, y añadimos el mutate que hace la magia: (across(c(h1:h5, a1:a5), ...) aplica la misma función a cada una de las diez columnas de lineup.
El que me conoce sabe lo que odio usar loops, pero si alguien sabe una mejor manera, por favor, que me lo diga. El loop for recorre el dataframe fila a fila. En cada posición[i] comprueba tres condiciones: que haya un jugador saliendo (player_out[i] no es NA), que haya un jugador entrando (player_in[i] no es NA) y que el valor actual de esa columna en esa fila sea exactamente el jugador que sale. Solo cuando las tres se cumplen actúa.
¿Por qué && y no solo &?
Porque el loop opera en contexto escalar, fila a fila. En cada iteración i se evalúa un único valor, no un vector.
& es vectorizado: compara elemento a elemento y devuelve un vector lógico del mismo largo. && evalúa solo el primer elemento y, si no peta: si la primera condición es FALSE, no evalúa las siguientes. Dentro de un if eso es exactamente lo que queremos, y de hecho R nos avisa si usamos & dentro de if porque espera un escalar, no un vector.
En este caso, además, qué pete nos es útil: si player_out[i] es NA, para ahí y no evalúa player_in[i] ni la comparación con col[i]. Con & evaluaría las tres condiciones igualmente.
La operación crítica es col[i:length(col)] <- player_in[i]. No reemplaza nada más la fila i: reemplaza desde i hasta el final del vector. Eso es lo que mantiene al nuevo jugador en pista para todas las jugadas siguientes. Cuando ese mismo jugador sea sustituido más adelante, otra iteración del loop lo reemplazará de nuevo desde esa nueva posición hacia delante.
El resultado es que, al terminar el mutate, cada fila del dataframe contiene los cinco jugadores reales en pista en ese momento del partido, no los titulares iniciales.
A continuación, vamos a intentar detectar los cambios de posesión
Con los lineups actualizados, el siguiente paso es definir cuándo cambia la posesión. Creamos una variable binaria, cambio_pos, que vale 1 cuando ocurre un evento que transfiere el balón:
clean_pbp <- clean_pbp %>%
mutate(
cambio_pos = case_when(
type_text == "Turnover" ~ 1,
type_text == "Defensive Rebound" ~ 1,
type_text == "Free Throw" & scoring_play ~ 0,
scoring_play & shooting_play ~ 1,
type_text == "Offensive Foul" ~ 1,
type_text == "Jumpball" ~ 1,
TRUE ~ 0
),
possession_id = cumsum(cambio_pos)
)El orden de los case_when es importante. Los tiros libres anotados no cambian la posesión porque el equipo puede seguir tirando, así que los excluimos explícitamente antes de evaluar el resto de scoring_play. Un robo, un rebote defensivo, una canasta de campo: todos transfieren el balón. cumsum() convierte esa secuencia de unos y ceros en un contador acumulado que identifica cada posesión de forma única.
Asignar el equipo en posesión
Cada jugada tiene un team_id que indica qué equipo ejecuta la acción, pero hay jugadas sin equipo asignado: tiempos muertos, eventos administrativos, faltas técnicas. Para cubrirlas usamos fill():
clean_pbp <- clean_pbp %>%
mutate(
possession_team = team_id
group_by(possession_id) %>%
fill(possession_team, .direction = "downup") %>%
ungroup()
)Agrupamos por possession_id y propagamos el team_id en ambas direcciones dentro de cada posesión. Las jugadas sin equipo heredan el valor de sus vecinas dentro del mismo segmento.
Equipo atacante y equipo defensor
Con el equipo en posesión definido, asignar atacante y defensor es fácil:
clean_pbp <- clean_pbp %>%
mutate(
offense_team = possession_team,
defense_team = if_else(possession_team == home_team_id, away_team_id, home_team_id)
)Si el equipo que ataca es el local, el defensor es el visitante, y viceversa.
Construir el lineup como cadena de texto
El último paso es convertir las columnas h1:h5 y a1:a5 en una cadena única por fila:
mutate(
home_lineup = pmap_chr(across(h1:h5), ~ paste(sort(c(...)), collapse = "|")),
away_lineup = pmap_chr(across(a1:a5), ~ paste(sort(c(...)), collapse = "|"))
)¿Qué hace pmap_chr()? aplica una función fila a fila sobre varias columnas a la vez. Dentro ordenamos los nombres con sort() antes de pegarlos. El orden garantiza que el mismo conjunto de cinco jugadores siempre produce exactamente la misma cadena, independientemente del orden en que aparezcan en el dataframe. Sin eso, "A|B|C|D|E" y "C|A|E|B|D" serían dos lineups distintos para cuando intentemos agrupar los datos, aunque sea el mismo quinteto.
Envolver todo en una función y aplicarla a varios partidos
Con la transformación completa, la empaquetamos en get_clean_pbp(), que recibe un game_id y devuelve el play-by-play enriquecido y así aplicarla a la lista de partidos que hemos obtenido cuando extrajimos el calendario del equipo; he aquí la función:
get_clean_pbp <- function(game_id) {
pbp <- hoopR::espn_mbb_pbp(game_id)
rosters <- hoopR::espn_mbb_player_box(game_id)
starters <- rosters %>%
select(game_id, home_away, display_name = athlete_short_name, team_id, starter,
athlete_display_name) %>%
filter(starter) %>%
group_by(game_id, home_away) %>%
mutate(etiqueta = paste0(substr(home_away, 1, 1), row_number())) %>%
ungroup() %>%
select(game_id, etiqueta, athlete_display_name) %>%
pivot_wider(names_from = etiqueta,
values_from = athlete_display_name)
names <- rosters %>%
select(athlete_id, athlete_display_name)
prev_pbp <- pbp %>%
left_join(names %>% rename(player_1 = athlete_display_name),
by = c("athlete_id_1" = "athlete_id")) %>%
left_join(names %>% rename(player_2 = athlete_display_name),
by = c("athlete_id_2" = "athlete_id")) %>%
left_join(starters, by = "game_id") %>%
mutate(in_out = case_when(
type_text == "Substitution" & str_detect(text, "subbing in") ~ "in",
type_text == "Substitution" & str_detect(text, "subbing out") ~ "out",
TRUE ~ NA_character_
))
subs <- prev_pbp %>%
filter(type_text == "Substitution") %>%
select(id, game_id, team_id, player_1, in_out)
outs <- subs %>%
filter(in_out == "out") %>%
rename(player_out = player_1) %>%
group_by(team_id) %>%
mutate(sub_num = row_number()) %>%
ungroup()
ins <- subs %>%
filter(in_out == "in") %>%
rename(player_in = player_1) %>%
group_by(team_id) %>%
mutate(sub_num = row_number()) %>%
ungroup() %>%
select(team_id, player_in, sub_num)
cambios <- outs %>%
left_join(ins, join_by(team_id, sub_num)) %>%
select(id, team_id, player_out, player_in)
clean_pbp <- prev_pbp %>%
left_join(cambios, join_by(id, team_id)) %>%
select(id:player_2, player_out, player_in, h1:h5, a1:a5) %>%
mutate(across(
c(h1:h5, a1:a5),
~ {
col <- .
for (i in seq_along(col)) {
if (!is.na(player_out[i]) && !is.na(player_in[i]) && col[i] == player_out[i]) {
col[i:length(col)] <- player_in[i]
}
}
col
}
))%>%
mutate(
cambio_pos = case_when(
type_text == "Turnover" ~ 1,
type_text == "Defensive Rebound" ~ 1,
# 👇 primero excluyes FT
type_text == "Free Throw" & scoring_play ~ 0,
# 👇 luego el resto de tiros
scoring_play & shooting_play ~ 1,
type_text == "Offensive Foul" ~ 1,
type_text == "Jumpball" ~ 1,
TRUE ~ 0
),
possession_id = cumsum(cambio_pos),
# identificar equipo en posesión
possession_team = team_id
) %>%
group_by(possession_id) %>%
fill(possession_team, .direction = "downup") %>%
ungroup() %>%
# --- ofensiva / defensiva ---
mutate(
offense = possession_team == home_team_id,
defense = possession_team == away_team_id
) %>%
mutate(
offense_team = possession_team,
defense_team = if_else(possession_team == home_team_id, away_team_id, home_team_id)
) %>%
# --- lineups ---
mutate(
home_lineup = pmap_chr(across(h1:h5), ~ paste(sort(c(...)), collapse = "|")),
away_lineup = pmap_chr(across(a1:a5), ~ paste(sort(c(...)), collapse = "|"))
)
return(clean_pbp)
}
Todo esto lo llamaríamos con esto:
all_pbp <- map_dfr(game_id, ~ {
tryCatch(
get_clean_pbp(.x),
error = function(e) NULL
)
})
write_csv(all_pbp, "../aday_mara/csv/michigan_pbp.csv"
)Lo explico: map_dfr() itera sobre el vector de IDs y apila los resultados en un único dataframe. El tryCatch() hace que un partido con error no rompa el proceso entero: devuelve NULL y continúa. Si la API de ESPN falla en un juego puntual, el resto se procesa igual.
El resultado se escribe en CSV, está escrita mi ruta; asegúrate de que pones la tuya y ya tenemos la masa madre para calcular minutos, net rating y cualquier métrica de lineup. Eso lo veremos en siguientes capítulos. Más abajo dejo la función que extrae los nombres de los equipos masculinos de la NCAA, sus colores, sus logos y el código completo que extrae el PlayByPlay de Michigan Wolverines en la temporada 2025/26.
