

Cómo se hace: Gráficas de barras y plot de dispersión
Tres gráficas del post de Kurtinaitis + boxscore completo en CSV. A la primera invito yo.




Si eres de los que te has registrado para una suscripción premium a The Clean Shot, muchas gracias.
El código completo está al final del post
La idea es publicar un post gratuito los martes y el como lo hago los viernes, no se si llegaré pero esa es la intención.
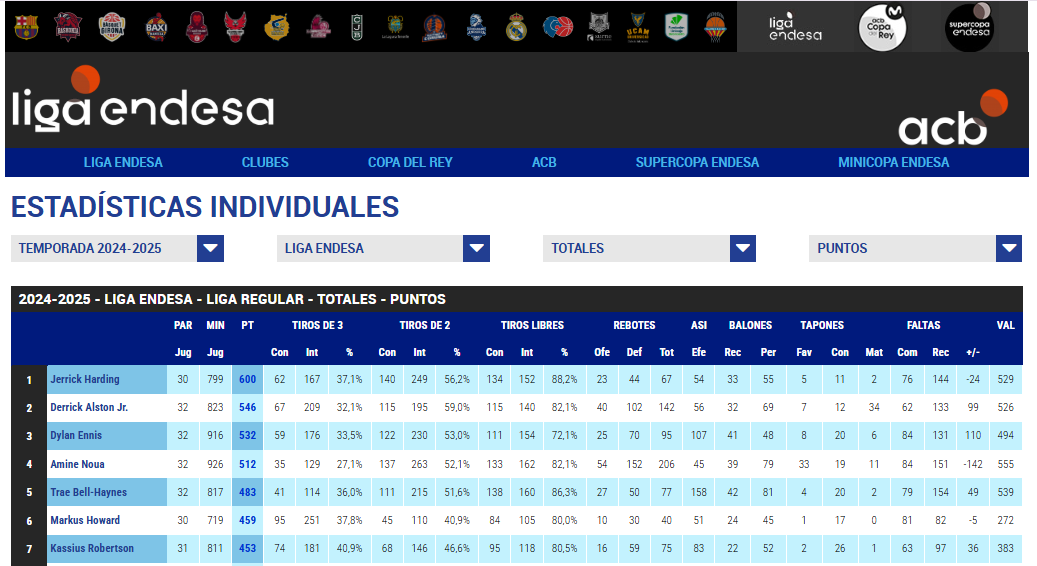
Esta semana quiero enseñar como extraigo las tablas de estadisticas individuales de ACB, como limpio los datos y como hago la gráfica final. Los datos de los gráficas de barras vienen de Las tablas de puntos y tiros de 3 con el filtro seleccionado en totales. La ACB filtra por los 50 mejores según la categoría.
Lo primero es cargar las librerias y ojo sé que son muchas
# 📚 Cargar las librerías-------------------
library(tidyverse) # manipulación datos
library(rvest) # scrapeo web
library(janitor) # limpiar tablas
library(shadowtext) # texto visible
library(prismatic) # ajustes color
library(ggtext) # texto enriquecido
library(cropcircles) # fotos redondas
library(glue) # concatenar texto
library(ggimage) # añadir imágenes
library(ggrepel) # evitar solapes
library(ggforce) # anotaciones extra
Luego cargo el data set con los datos de los equipos (logos, colores, nombre corto, etc.)
clubs <- read.csv("https://raw.githubusercontent.com/IvoVillanueva/logos_cuadrados_acb/refs/heads/main/acb_df.csv") %>%
mutate(color = ifelse(abb == "RMB", "white", color))#Aquí había puesto el color amarillo del Real Madrid pero me di cuenta que el blanco funciona muy bien tambiénLuego el tema personalizado de los plots
theme_ivo <- function (font_size = 9) {
theme_minimal(base_size = font_size, base_family = "Oswald") %+replace%
theme(
plot.background = element_rect(fill = 'white', color = "white"),
panel.grid.minor = element_blank(),
plot.title = element_text(hjust = 0, size = 14, face = 'bold'),
plot.subtitle = element_text(color = 'gray65', hjust = 0, margin=margin(2.5,0,10,0), size = 11),
)
}y la firma
twitter <- "<span style='color:#000000;font-family: \"Font Awesome 6 Brands\"'></span>"
tweetelcheff <- "<span style='font-weight:bold;'>*@elcheff*</span>"
insta <- "<span style='color:#E1306C;font-family: \"Font Awesome 6 Brands\"'></span>"
instaelcheff <- "<span style='font-weight:bold;'>*@sport_iv0*</span>"
github <- "<span style='color:#000000;font-family: \"Font Awesome 6 Brands\"'></span>"
githubelcheff <- "<span style='font-weight:bold;'>*IvoVillanueva*</span>"
caption <- glue::glue("**Datos**: *ACB.COM* | **Gráfico**: *Ivo Villanueva* • {twitter} {tweetelcheff} • {insta} {instaelcheff} • {github} {githubelcheff}")Ahora vamos ya a extraer la tabla con la libreria rvest
url <- "https://www.acb.com/estadisticas-individuales/puntos/temporada_id/2024/edicion_id/975/fase_id/107/tipo_id/0" %>%
read_html()
df <- url %>%
html_element("table") %>%
html_table() El resultado es super sucio. Con cosas que me dan mucho coraje cuando extraigo datos: como dobles columnas y columnas sin nombre por ejemplo

En este caso me da igual porque solo necesito dos columnas la del nombre y la de PT
df <- url %>%
html_element("table") %>%
html_table() %>%
row_to_names(1) %>% # le digo que ponga de nombre de columna la primera fila
clean_names() %>% #limpio los nombres
select( jugador = x, puntos = na_2) %>% #le doy nombres descripitivos
arrange(desc(puntos)) %>%
slice(1:20)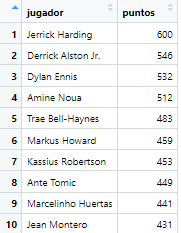
Esto ya otra cosa; al aviso que sale, ni caso. ahora ya tenemos los datos, y con esto ya se podría hacer el gráfico, pero para hacer la tabla de una manera mas vistosa y no tener que ir haciendolo a mano, la cosa se complica bastante:
Primero tenemos que inventarnos una tabla para extraer los ids de los jugadores y los nombres, para poder juntarlos mas adelante
jugadores <- tibble(
id= url %>%
html_elements("a.colorweb_7") %>%
html_attr("href") %>%
str_extract(., "[0-9]+"),#extrae solo el numero de la url
jugador = url %>%
html_elements("a.colorweb_7") %>%
html_text()) %>%
hablar::retype()Luego (y solo por esto te juro que los 5€ merecen la pena, porque cuando yo empecé ojala me lo hubiera explicado alguien) una función que genere una tabla que extraiga los nombres de los equipos y el código de la foto de la página del jugador y que me una todo de una vez
#jugadores$id es igual a [1] 30002017 30003416 20212941 etc
plot_df <- map_df(jugadores$id, function(x) {
jugador_html <- read_html(glue("https://www.acb.com/jugador/temporada-a-temporada/id/{x}"))
# Extraer equipo
equipo <- jugador_html %>%
html_element(".equipo span") %>%
html_text()
# Extraer URL de foto
foto <- jugador_html %>%
html_element(".datos img") %>%
html_attr("src") %>%
str_extract(., "[^/]+(?=\\.jpg)")
# [^/]+ = todo lo que no sea "/", es decir, el nombre del archivo.
# (?=\\.jpg) = lookahead para asegurarse de que lo que viene después sea .jpg, pero sin incluirlo.
# Crear tibble con todo
tibble(equipo = equipo, foto = foto, id = x) %>%
left_join(jugadores, join_by(id)) %>%
left_join(clubs %>% select(equipo, color), join_by(equipo)) %>%
inner_join(df, join_by(jugador)) %>%
hablar::retype()
})
Cuando correis la función tarda un rato porque va por cada url, o sea 20 en total, extrayendo los datos que necesitamos y este es el resultado, se puede pensar que son mucho dato pero lo usaremos todos mas adelante

Creamos la base del gráfico
p <- plot_df %>%
ggplot(aes(x = puntos, y = fct_reorder(jugador, puntos)))
Agregamos las barras horizontales. Cada jugador tiene el color de su equipo.
p <- plot_df %>%
ggplot(aes(x = puntos, y = fct_reorder(jugador, puntos))) +
geom_col(aes(fill = color,
color = after_scale(clr_darken(fill, 0.15))),
alpha = .9,
width = 0.6)
Al final de las barras se colocan un geom_point para reforzar visualmente el valor.
p <- plot_df %>%
ggplot(aes(x = puntos, y = fct_reorder(jugador, puntos))) +
geom_col(...) +
geom_point(shape = 21, size = 7.6,
aes(fill = color,
x = puntos,
color = after_scale(clr_darken(fill, 0.3))))
Mostramos los puntos de cada jugador dentro del geom_point, con sombra negra para que se lean bien.
p <- plot_df %>%
ggplot(aes(x = puntos, y = fct_reorder(jugador, puntos))) +
geom_col(...) +
geom_point(...) +
geom_shadowtext(aes(x = puntos, y = jugador, label = puntos, family = "Roboto"),
bg.r = .15, fontface = 'bold',
bg.colour = "black", color = 'white',
hjust = .5, size = 2.85)
Ajustamos los límites del eje X y añadimos título y subtítulo.
p <- p +
scale_fill_identity() +
scale_x_continuous(limits = c(0, 700), breaks = seq(0, 800, 100)) +
labs(
x = "",
y = "",
title = "Top 20 Anotadores 2025",
subtitle = "Puntos totales hasta J32 | Liga Endesa"
)
Aplicamos mi tema personalizado (prueba a modificar el mio o con el que mas te guste) y ajustamos texto, márgenes y estilos.
p <- p +
theme_ivo() +
theme(
panel.grid.major.y = element_blank(),
legend.position = 'none',
axis.title = element_blank(),
plot.caption = element_markdown(size = 7, hjust = 0),
plot.title = element_text(face = "bold", size = 26),
plot.subtitle = element_text(size = 10.5),
plot.margin = margin(b = 25, t = 25, r = 25, l = 25),
axis.text = element_text(size = 10)
)
Guardamos el gráfico como imagen en alta calidad para usar en redes o posts.
ggsave("anotadores.png", p, width = 6.25, height = 7, dpi = 600)
🔒 Continúa para suscriptores de pago
Hasta aquí, explico cómo se construye la primera de las tres gráficas del post.
A partir de aquí:
Código completo de las otras dos (triplistas y dispersión)
Comentarios paso a paso
Exportación y CSV con todos los boxscore hasta la J32 (Rows: 7180, Columns: 72)
Gracias por apoyarme 👇
