

Cómo se hace: Extraer Play By Play API Euroliga
Con Python y cómo crear un Dataframe usable y amigable.

Tras unos días de descanso pensando en cosas…

Bueno, pensando en la nada. 😅; hablando con algunos suscriptores premium me surgió la idea de crear algo útil también en Python, además de R. No porque sea más fácil (¡no lo es!), sino porque es un lenguaje más popular y quizá más accesible para mucha gente.
👉 En este post voy a mostrar la forma más sencilla de conseguir datos de la Euroliga usando la librería euroleague_api. Más adelante, también en exclusiva para suscriptores premium, compartiré el camino difícil: cómo extraer los datos directamente de la página oficial de Euroleague.
De momento voy a dar por hecho que tenéis unas nociones básicas de Python y Jupyter Notebooks (yo suelo trabajar en VSCode).
También aviso: para el data wrangling voy a usar Polars en lugar de Pandas. ¿La razón? Viniendo del Tidyverse de R, Pandas me parece un dolor de muelas y una castaña.
A mí me gusta escribir el código en Notebooks porque me permite controlar mejor cada resultado.
Instalación de librerías
Si aún no tienes las librerías, abre tu terminal y escribe:
pip install -U pyjanitor polars euroleague-api El parámetro
-Uactualiza a la última versión en caso de que ya las tengas instaladas.
Primeros imports en Python
import polars as pl
import janitor.polars
from euroleague_api.play_by_play_data import PlayByPlayCon esto ya tenemos lo necesario para empezar a trabajar.
En este ejemplo vamos a extraer el play-by-play completo de la última temporada en Euroliga.
Aquí tienes el enlace a toda la documentación de la API por si prefieres sacar cualquier otro dataset disponible.
(Tip: para EuroCup solo hay que cambiar la “E” por la “U”. El año siempre corresponde al primero de la temporada: por ejemplo, la 24-25 se escribe como 2024).
competition_code = "E" # Rrecuerda EuroLeague ("E"), EuroCup suele ser "U"
# 1) Instanciar
pbp = PlayByPlay(competition_code)
# 2) Descargar toda la temporada (devuelve pandas.DataFrame)
pbp_df = pbp.get_game_play_by_play_data_single_season(season=2024)Así es como lo veo yo, y así se vería si trabajas con VSCode y Jupyter Notebooks, tal como comenté antes
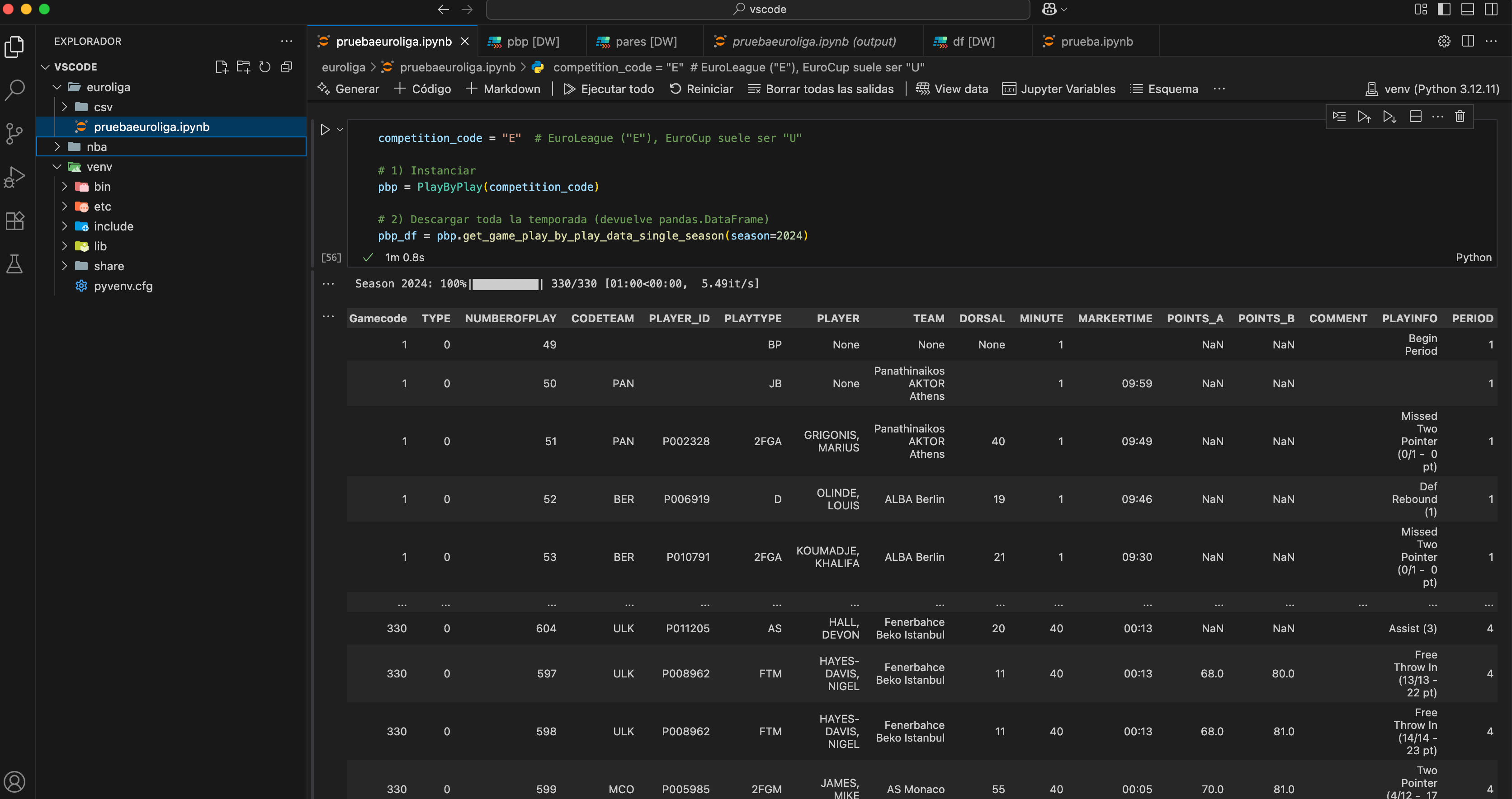
La API te devuelve un DataFrame de Pandas, bastante malo (de los peores que he descargado, solo comparable al de la primera FEB). Para poder trabajar con Polars hay que convertirlo a un DataFrame de Polars, y para eso necesitamos tener instalado ipywidgets. Así que, por si acaso, aquí te dejo el pip
#Escribimos en el terminal
pip install -U ipywidgetsOk, ya tenemos el widget instalado, ahora lo convertimos a un dataframe de Polars.
df = pl.from_pandas(pbp_df)Ya tenemos el play-by-play, pero no es muy usable tal y como viene. Así que vamos a transformarlo en algo con lo que realmente podamos trabajar y calcular datos. Lo primero que me llama la atención es la columna PLAYINFO: describe el tipo de jugada, los intentos realizados/convertidos y los puntos acumulados por el jugador. Nosotros vamos a usar únicamente la jugada y los puntos. En lugar de complicarnos con un regex que extraiga, separe y construya nuevas columnas, lo haremos de una forma más sencilla.
Hasta aquí la parte abierta de este tutorial. Hemos preparado el terreno, instalado librerías y visto cómo luce el play-by-play en bruto.
A partir de aquí viene lo interesante: cómo transformar esos datos en un formato realmente útil para analizarlos. Te enseño paso a paso cómo limpiar la columna
PLAYINFO, generar variables nuevas y empezar a construir métricas desde cero.👉 Todo eso lo encontrarás en la parte premium del post. Si quieres seguir y acceder al código completo con explicaciones detalladas, suscríbete a la versión de pago y apoya este proyecto.
