

Cómo pasé de ejecutar scripts manualmente a un sistema que se actualiza solo cada madrugada
El día que dejé que GitHub hiciera mi trabajo con los boxscores de la Euroliga


¿Te da pereza copiar o actualizar funciones cada vez que empiezas un script nuevo?
Cuando era pequeño, allá por el siglo XX, vi una película que me obsesionó y que nunca supe el nombre (la pille empezada). Digamos que era una película de unas naves espaciales que llevaban unos invernaderos para preservar la naturaleza que el hombre había destruido. Los jardineros eran unos robots que, ajenos a todo, seguían haciendo su trabajo con delicadeza y constancia, vigilando cada hoja y cada brote sin necesidad de reconocimiento, solo instrucciones claras y una misión. Todo ello bajo la mirada indiferente de unos humanos que no querían estar allí. Durante años no supe cómo se llamaba, pero gracias a ChatGPT di con el título: Silent Running.
A veces pienso en ellos cuando veo cómo trabaja una GitHub Action, como hacía el protagonista mientras comía chirimoyas y miraba a los robots seguir con su rutina. No tienen ojos ni ruedan por pasillos de metal, pero tienen algo de esos robots: ejecutan su tarea en silencio, a la hora indicada.
En este tutorial voy a crear mis propios robots con GitHub Actions para automatizar esas tareas que todos odiamos y que me rieguen el jardín de los datos recopilandolos y guardando los más recientes.
Por ejemplo, los boxscore de los partidos de Euroliga que se juegan a lo largo de la semana.
La semana pasada expliqué cómo extraerlos directamente desde la web de estadísticas. En este post, te enseño cómo mantenerlos actualizados automáticamente, sin tener que ejecutar el código manualmente cada día.
Y la próxima semana, voy un paso más allá: te mostraré cómo convertirlo en una librería lista para usar.
Si quieres que tus datos trabajen por ti (y no al revés), suscríbete y sigue la serie.
Cómo uso GitHub Actions
Presupongo que tienes conocimientos básicos de Git/GitHub. Es decir, que ya tienes una cuenta GitHub, sabes qué es un repositorio y entiendes cómo confirmar cambios, etc.
Si eres completamente nuevo en GitHub, te recomiendo leer primero alguna guía de inicio. Puedo recomendar Happy Git y GitHub para usuarios .
Voy a configurar un action de GitHub para recopilar y guardar de martes a Sabado los Boxscore. Es un ejemplo de cómo creo un flujo de datos automatizado, así mostrar el gran potencial de los action de GitHub.
Lo primero que haré será crear un nuevo repositorio. Lo llamaré BOXSCORES-EUROLEAGE, llamadme original.
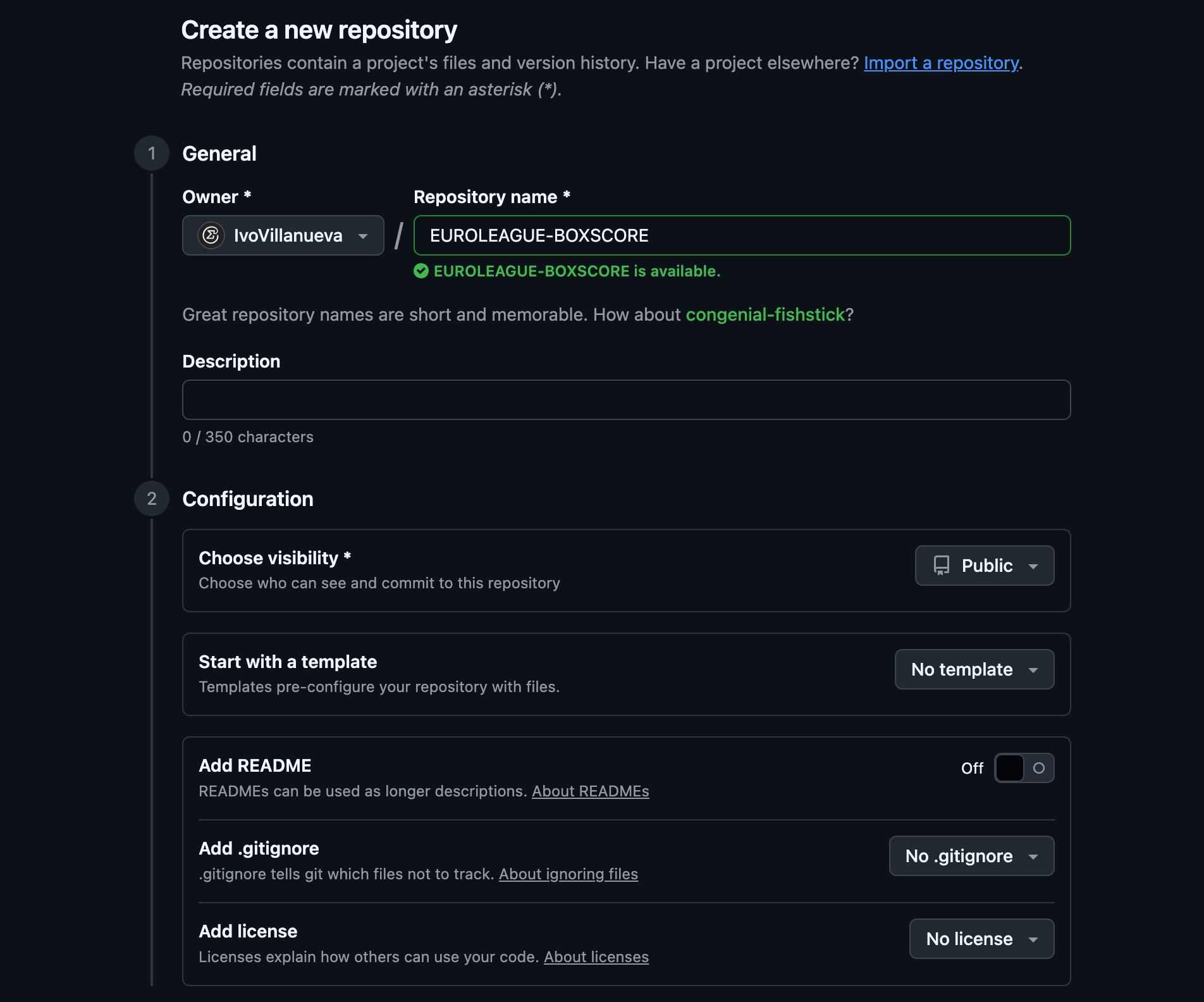
Luego bajo hasta Add .gitignore y no me complico la vida elijo el template por. omisión de R. Como se puede ver esto sirve para ingnorar archivos temporales, etc.
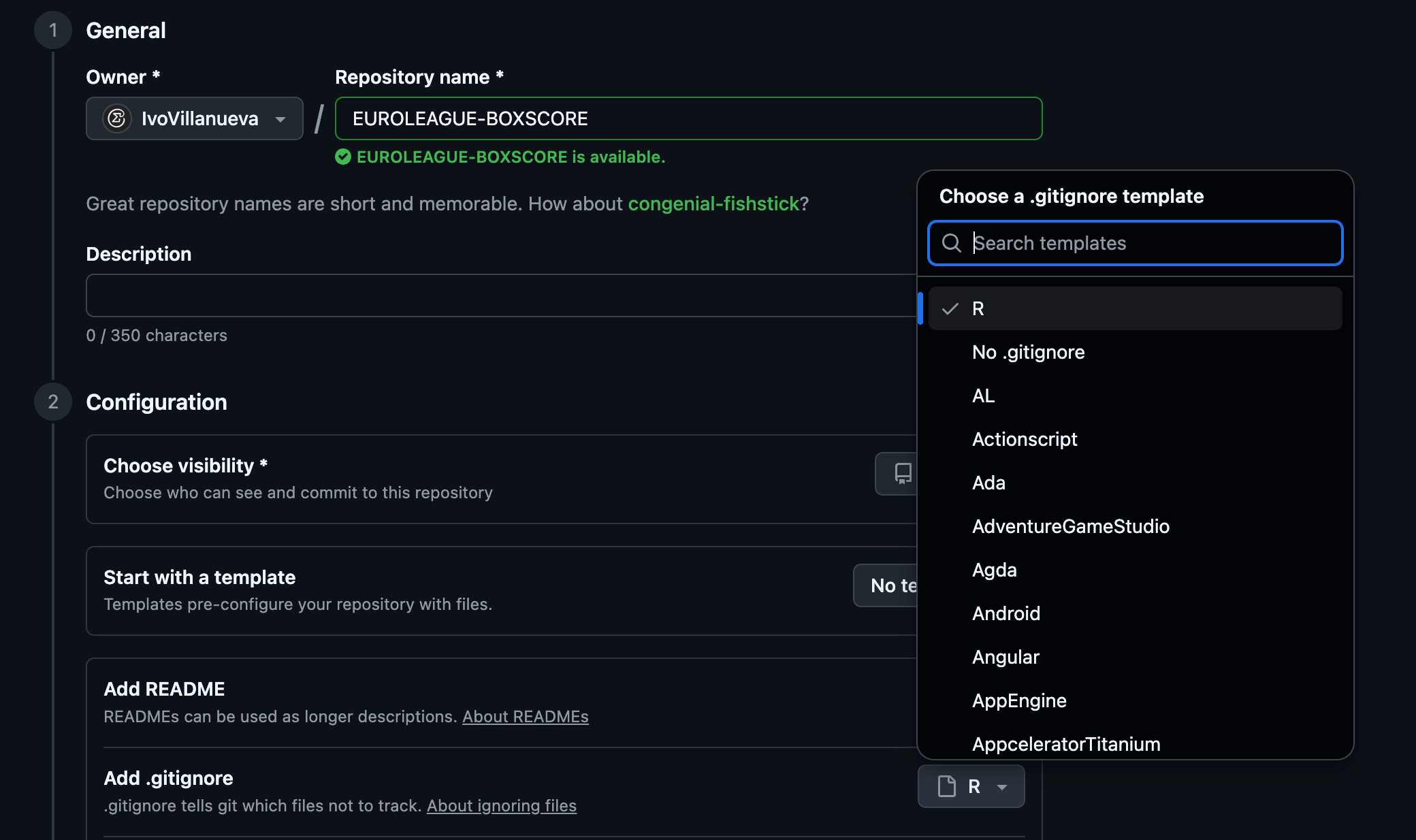
Ahora desplego Add file
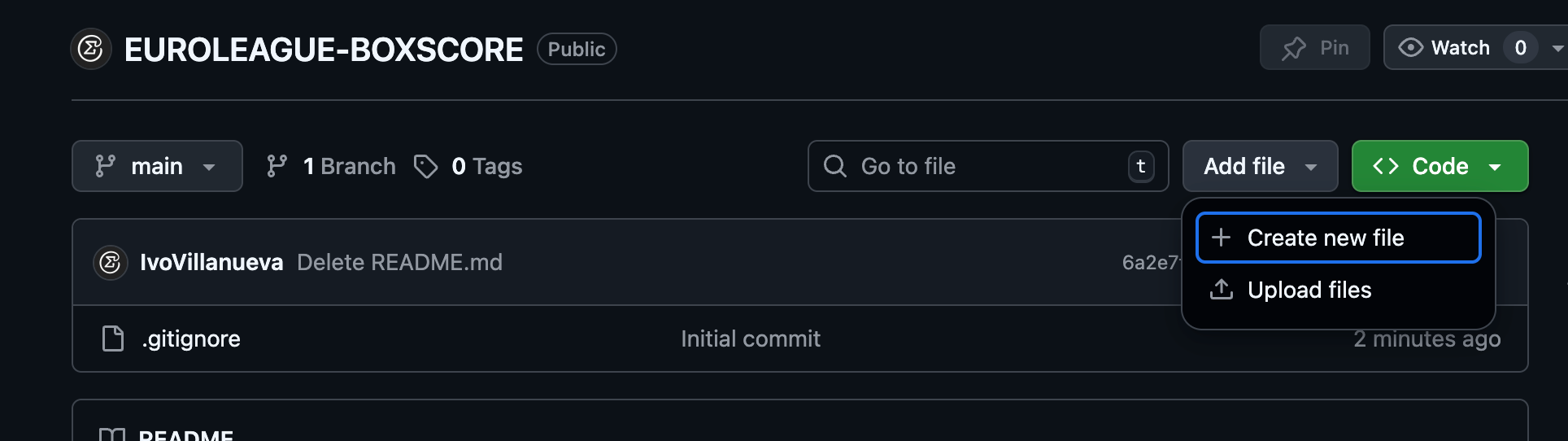
Y pego la función de la semana pasada, como indico en el código he agregado la fecha para controlar cuando ha sido la última vez que se han descargado los datos. Como sabeis este código extrae los Boxscore y crea un .csv y lo guarda en una carpeta que se llama Data
#librerias
library(tidyverse)
library(jsonlite)
library(httr)
library(lubridate)
library(janitor)
# asegurar que la carpeta data existe
if (!dir.exists(”data”)) dir.create(”data”)
#cargar las jornadas
ronda_df <- read_csv(
“https://raw.githubusercontent.com/IvoVillanueva/Euroleague-boxscores/refs/heads/main/gamecodes/gamecodes_2025-26.csv”,
show_col_types = FALSE,
progress = FALSE
)
#extraer los codigos de partidos hasta la fecha
gamecode <- ronda_df %>%
arrange(jornada, gamecode, date) %>%
filter(date < today(tzone = “Europe/Madrid”)) %>%
pull(gamecode)
#función que extrae los boxscores
boxscores_fn <- function(gamecode) {
url <- paste0(”https://live.euroleague.net/api/Boxscore?gamecode=”, gamecode, “&seasoncode=E2025”)
round <- ronda_df %>%
rename(codigo = gamecode) %>%
arrange(jornada, codigo) %>%
filter(codigo == gamecode) %>%
pull(jornada)
#agrego esta parte para poner la fecha de la extracción
fecha <- ronda_df %>%
rename(codigo = gamecode) %>%
arrange(jornada, codigo) %>%
filter(codigo == gamecode) %>%
pull(date)
raw_teams <- GET(url, query = list()) %>%
content()
tm <- pluck(raw_teams, “Stats”) %>%
tibble(value = .) %>%
unnest_wider(value) %>%
select(Team)
df <- pluck(raw_teams, “Stats”, 1, “PlayersStats”) %>%
tibble(value = .) %>%
unnest_wider(value) %>%
mutate(
team_name = tm$Team[1],
opp_team_name = tm$Team[2],
id_match = gamecode
)
df1 <- pluck(raw_teams, “Stats”, 2, “PlayersStats”) %>%
tibble(value = .) %>%
unnest_wider(value) %>%
mutate(
team_name = tm$Team[2],
opp_team_name = tm$Team[1],
id_match = gamecode
)
df2 <- rbind(df, df1) %>%
select(id_match, Player_ID:opp_team_name) %>%
clean_names() %>%
mutate(
isLeague = “euroleague”,
player_id = str_squish(player_id),
ronda = round, .before = id_match,
date = fecha
)
}
boxscores_df <- map_df(gamecode, boxscores_fn)
#escribir el dataframe en la carpeta “data/”
write.csv(boxscores_df, “data/euroleague_boxscore_2025_26.csv”, row.names = F)