

Cómo hacer Great Tables en Python y R
Incluyo el código completo en ambos lenguajes.

Hola a todos,
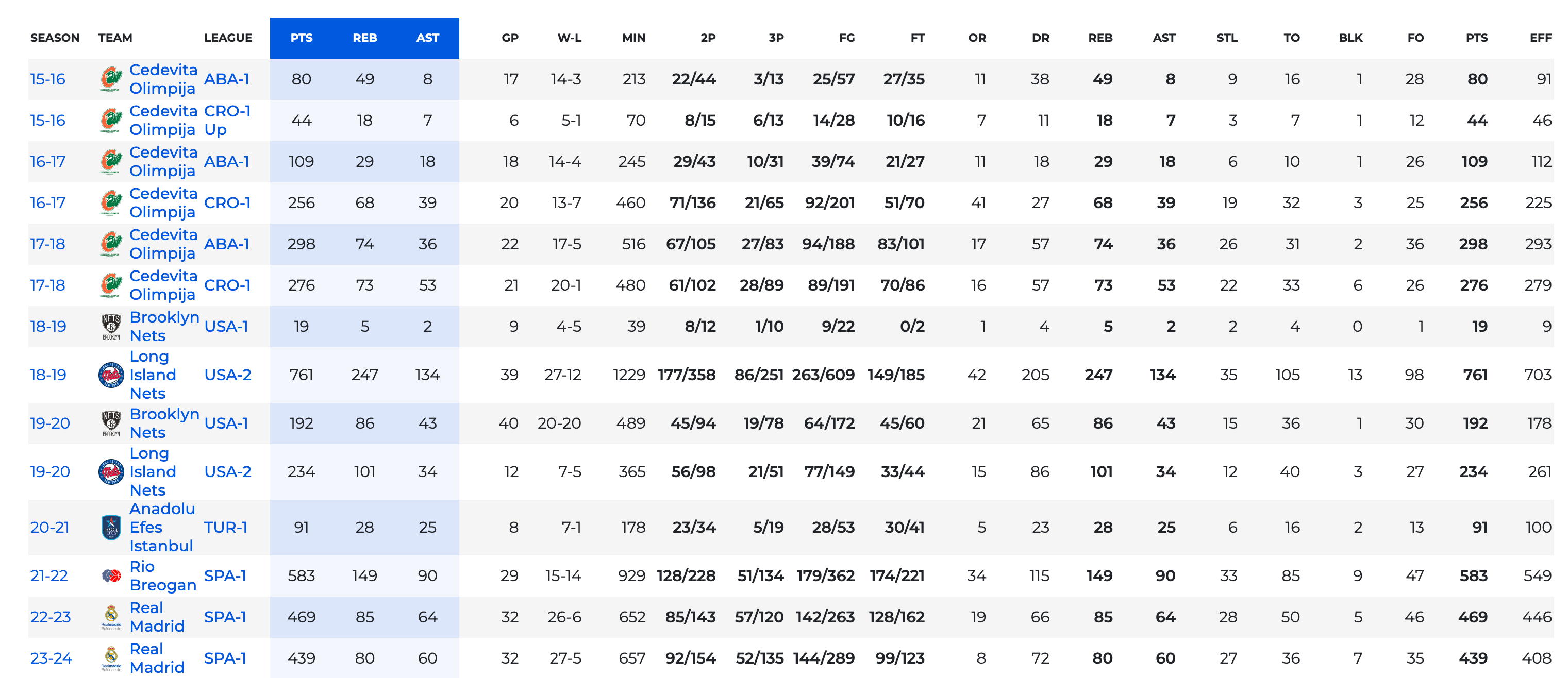
El tutorial de hoy muestra cómo cree esta tabla en Python y en R. De la página de Proballers.com

Mi lenguaje principal es R y es con el que hago los ánalisis porque lo tengo mas automatizado y porque hasta ahora la calidad de las visualizaciones estaban, a mi parecer, a años luz (de mejores) de las de Python. Pero con la implementación de la librerías gt() y gtExtras() (great_tables gt_extras en Python) ahora ya el lenguaje que elijas es igual, reconozco que Python es mucho más popular y es el que conoce y piden en todos lados, y aunque todavía no está igual al 100%, por ejemplo no está intregrado poner superindices, que es la diferencía fundamental con la tabla hecha con R, si que el 98% es prácticamente igual.
Comenzaremos en Python y luego paseremos a R
Código en Python 🐍
Empezamos cargando las librerías
import polars as pl, pandas as pd, requests #extraer, transformar, cargar, descargar Json
from bs4 import BeautifulSoup # parsear HTML
from urllib.parse import urljoin # rutas absolutas
from great_tables import GT, md, loc, style # tabla GT / formatos
import gt_extras as gte # extras GT (resaltados)
import polars.selectors as cs # seleccionar numéricas
from selenium import webdriver # exportar PNG (GT)
from PIL import Image, ImageOps # margen PNG (post)Aprovecho para recordar que uso Jupiter NoteBooks, por lo que cada bloque de código es un chunk en el archivo original mi escritorio se ve así:
Comentar que escribo el código Python como si estuviera escribiendolo en R, por lo que a lo mejor es diferente a lo que se ve en otros lados.
Cargamos la url, y mediante pandas y polars extraemos la primera tabla por eso el [0], limpiamos y corregimos los nombres de las columnas, las seleccionamos, cambiamos el nombre de eff por el de val. Como la tabla son totales, dividimos todo por los partidos jugados y redondeamos, solo a minutos (sin segundos) la columna min, y las demás con 1 decimal
url = "https://www.proballers.com/basketball/player/65439/dzanan-musa/totals"
df = (
pl.from_pandas(pd.read_html(url, storage_options={"User-Agent": "Mozilla/5.0"})[0])
.clean_names(remove_special=True, strip_underscores=True)
.select(
"season",
"team",
"league",
"gp",
"min",
"pts",
"reb",
"ast",
"stl",
"to",
"blk",
pl.col("eff").alias("val"),
)
).with_columns(
((cs.numeric().exclude("gp", "min")) / pl.col("gp")).round(1), # todas las numéricas ≠ gp,min
((pl.col("min") / pl.col("gp")).round().cast(pl.Int8)), # min: 0 decimales
)
df El resultado de este bloque se ve en la foto de arriba
Ahora necesitamos una serie de datos en forma de tablas para enriquecer los datos y poder conseguir una visualización que den ganas de verla.
Tenemos que extraer a parte, los logos, los nombres de los equipos y hacer una tabla con el fin de unirla a la de los datos. Esto ya lo expliqué en otros tutoriales: botón derecho y buscamos los elementos.
Un detalle al final verás que hay una linea (.unique) que es para quitar de la tabla los nombres que se repiten, debido a los años que juega en cada equipo. Si los dejaramos, nos duplicaría al unir la tabla tantas veces como se repitiera el nombre.
# Dataframe con los nombres de equipo y sus logos
headers = {"User-Agent": "Mozilla/5.0"}
res = requests.get(url, headers = headers)
soup = BeautifulSoup(res.text, "html.parser")
links = soup.select(".show .second__left img[src]") #logos
links2 = soup.select(".show .second__left a[title]") # nombres de equipo
#Tabla con ambas cosas
dfLogos = pl.DataFrame({
"team": [a.get_text(strip=True) for a in links2],
"url_logo": [img["src"] for img in links]
}).unique(subset=["team"], keep="first", maintain_order=True)

Disclaimer:
Estas tareas tan minuciosas y tediosas —como hacer tablas de equivalencias entre los nombres de liga en Proballers y sus nombres reales, o buscar los colores oficiales de los equipos— me llevarían unos cuantos minutos si tuviera que hacerlas a mano.Pero se resuelven con algo tan simple como pedirle a ChatGPT que busque esas equivalencias por mí… y que me monte una tabla con lo que necesito.
Hacemos una con las de las ligas (GPT)
ligas = pl.DataFrame(
{
"league": ["ABA-1", "CRO-1 Up", "CRO-1", "USA-1", "USA-2", "TUR-1", "SPA-1"],
"liga": ["ABA League", "Premijer Liga (Fase por el título)", "Premijer Liga (Croacia)",
"NBA", "G League", "BSL (Türkiye)", "ACB"],
},
) # categoriza 'league'
ligasA partir de aquí, me harías muy feliz si me ayudas a sacar este proyecto adelante mejorando tu suscripción.
Gracias por adelantado.
