


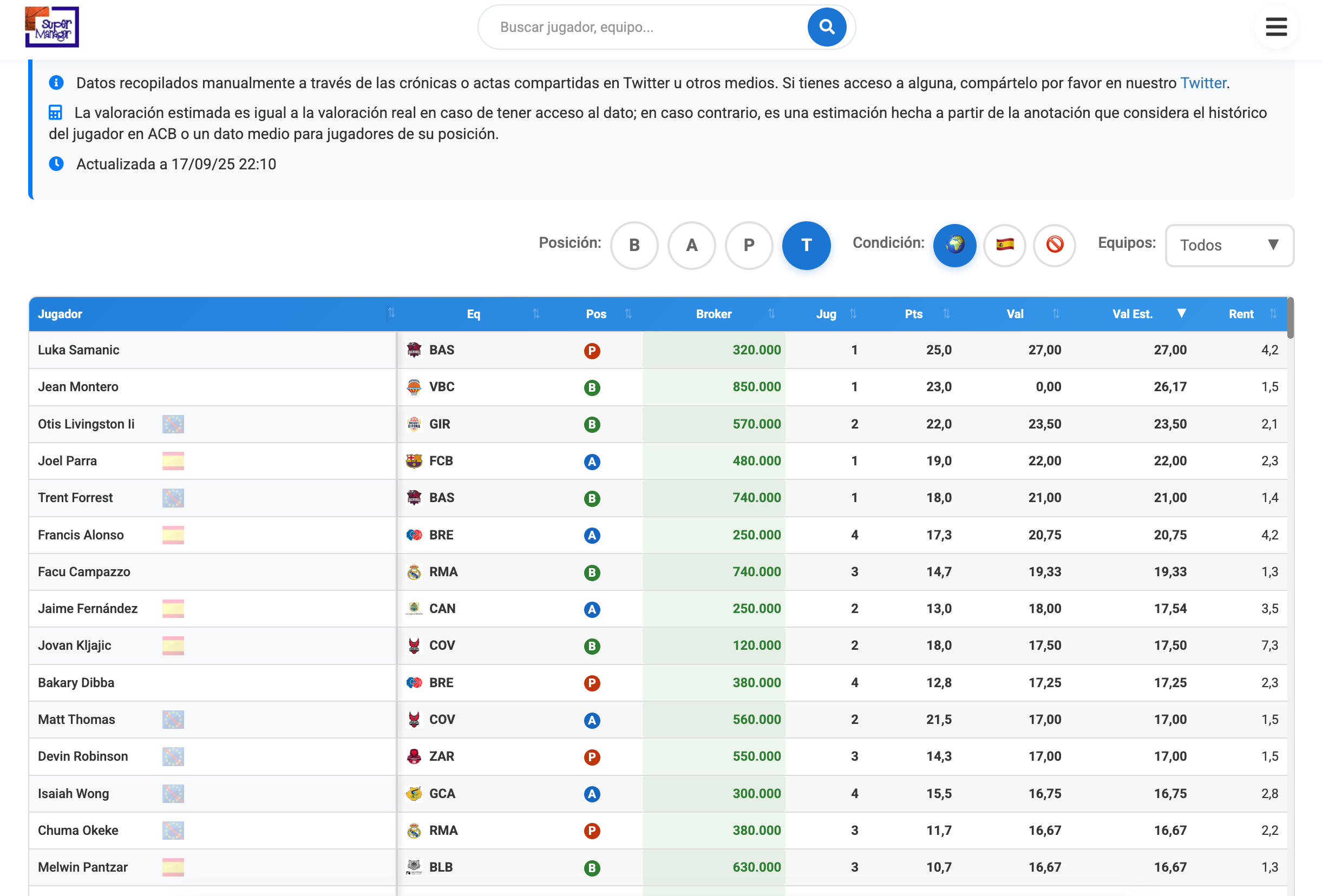
Todo el mérito y el crédito para El Rincón: esta tabla se la curra a mano, metiendo uno a uno los datos a partir de las fotos de las actas de los partidos. Es una información muy importante e imprescindible. Pero, la extracción tiene cierta dificultad que me sirve estupendamente para mis fines pedagógicos.
Este tutorial va a explicar como hacerlo en 🐍 y y en R 💻.
🐍 Código en Python
No me voy a entretener mucho explicando cada línea. Vamos a lo práctico, que es lo que interesa.
Cargamos las librerías
Las típicas para scraping, limpieza y manipulación de datos:
import pandas as pd
import polars as pl, requests
import janitor.polars
from bs4 import BeautifulSoupCreamos un elemento con la URL
Vamos a trabajar con la web de pretemporada del Rincón. Aquí está el enlace:
url = "https://www.rincondelmanager.com/smgr/pretemporada.php"Extraemos los nombres de los jugadores y su bandera
Las filas no siempre coinciden, así que añadimos una condición para evitar errores cuando el div con la bandera está vacío. Si no hay bandera, devuelve NULL
headers = {"User-Agent": "Mozilla/5.0"}
res = requests.get(url, headers = headers)
soup = BeautifulSoup(res.text, "html.parser")
jugador = soup.select(".jugador a[href]")
dfbanderas = pl.DataFrame({
"jugador": [a.get_text(strip=True) for a in jugador],
"bandera": [
" ".join(j.find("div").get("class"))
if (j.find("div") is not None and j.find("div").get("class"))
else None
for j in jugador
]
})
dfbanderas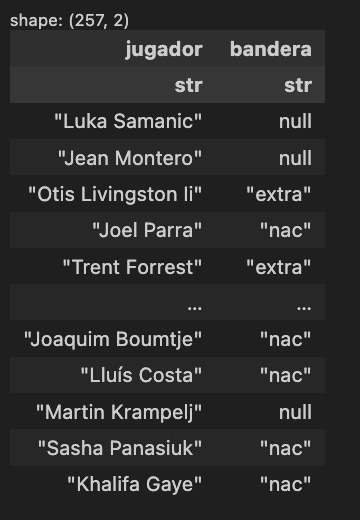
Extraemos la tabla principal
Usamos read_html desde pandas y luego convertimos a polars, limpiando los nombres para que no haya líos con espacios, tildes, etc.
url = "https://www.rincondelmanager.com/smgr/pretemporada.php"
df = pl.from_pandas(
pd.read_html(
url, thousands=".", decimal=",", storage_options={"User-Agent": "Mozilla/5.0"}
)[0]
).clean_names(remove_special=True, strip_underscores=True)
df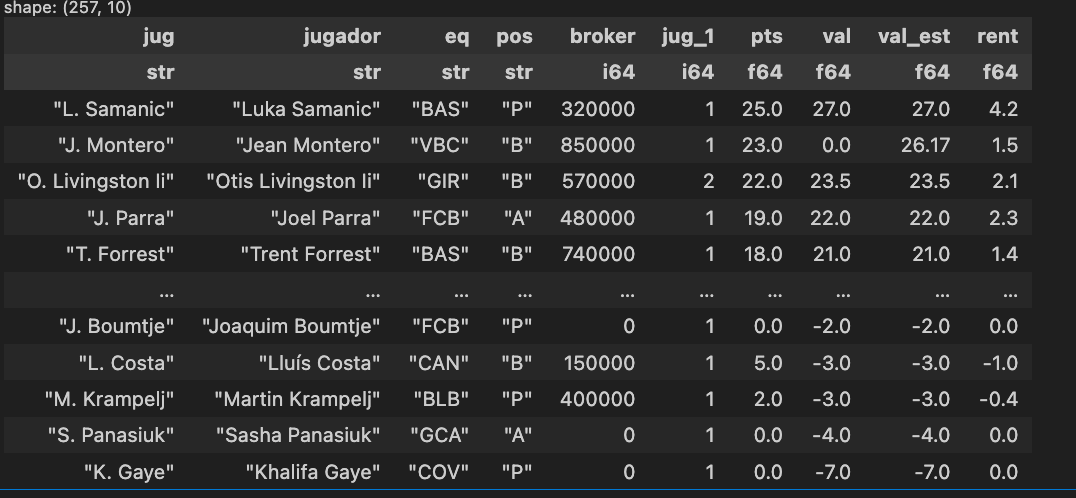
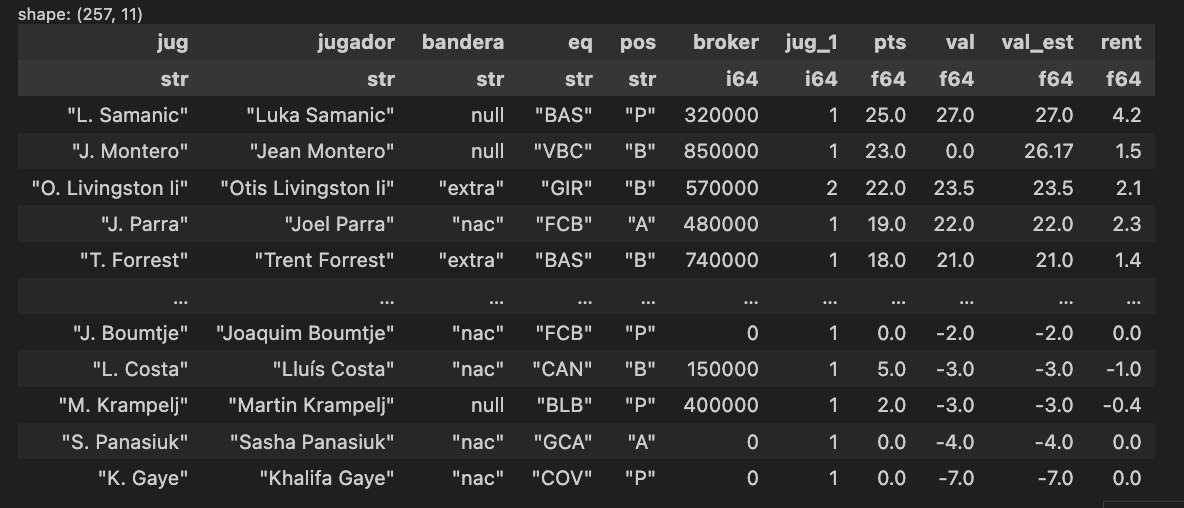
Juntamos las dos tablas
Hacemos un join por el nombre del jugador y seleccionamos solo las columnas clave, ya ordenadas:
tabla = (df.join(dfbanderas, on="jugador", how="left")
.select(["jug", "jugador", "bandera", "eq", "pos", "broker", "jug_1", "pts", "val", "val_est", "rent"]))
tablaY ya estaría. Una tabla limpia, con nombres, banderas y todas las estadísticas ordenadas. Sin tocar nada a mano y lista para usar en lo que necesites.
💾 Guardamos el archivo en CSV
Para terminar, guardamos la tabla final en un .csv, que siempre viene bien tenerlo listo para reutilizar:
tabla.write_csv("tabla_pretemporada.csv")🧪 Código en R
Ahora sí, vamos con R. Aquí no hay complicación ni magia negra, pero sí algunas cosas que conviene explicar para que todo funcione bien.
Cargamos las librerías
Necesitamos las de siempre para scraping y manipulación básica:
library(tidyverse)
library(rvest)
library(janitor)
library(xml2)