

Cómo Extraer Datos De Los PDFS ACB
Y de cómo El Rincón del Supermanager se convierte en el Rincón del Superheroe cuando llega la pretemporada de la ACB.

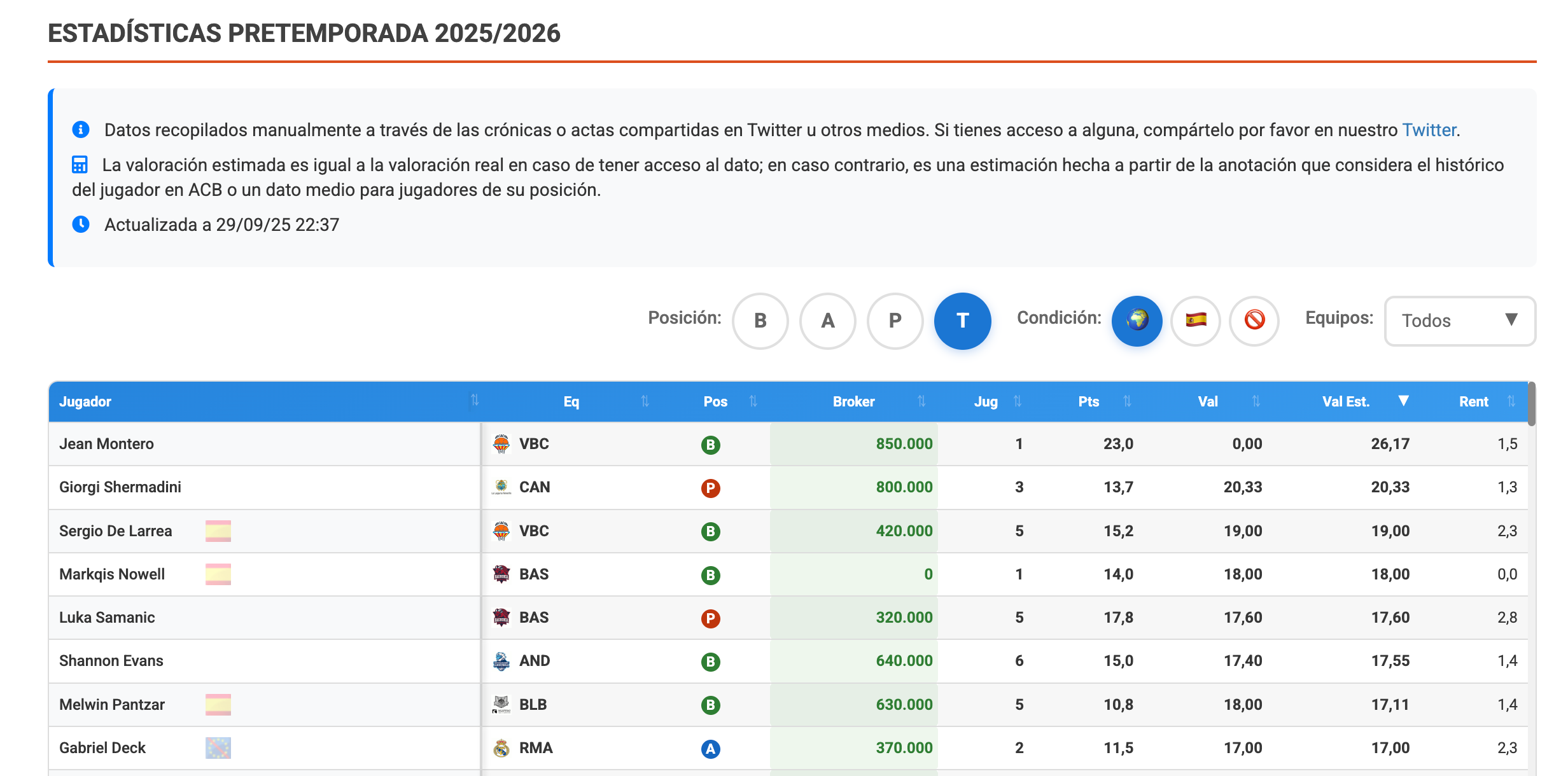
La pretemporada siempre es un suplicio para extraer datos. Las estadísticas de los partidos de preparación, ACB las incluye con un enlace dentro de la crónica (a veces) que, al pincharlo, nos lleva a un PDF en el mejor de los casos o a un JPG en el peor. En este contexto además nos podemos encontrar que el acta sea en el formato de la ACB, que de paso hay que decir está fenomenal, pero en muchos otros son cada uno de su padre y de su madre.

Tanto suplicio es, que yo hace algunos años lo di por imposible o inabarcable. Pero en esto apareció El Rincón del SuperManager y su farol como el superhéroe salvador y de manera altruista y artesana (a manini) decidió salvarnos a todos de esta época oscura de información o desinformación
Para pagar en parte mi deuda, voy a explicar o tratar de explicar y mecanizar, cómo convertir estos archivos del demonio en algo manejable y trabajable.
Comencemos
Lo primero es saber dónde extraer los enlaces de los partidos de pretemporada. Así que nos vamos a la página oficial de ACB
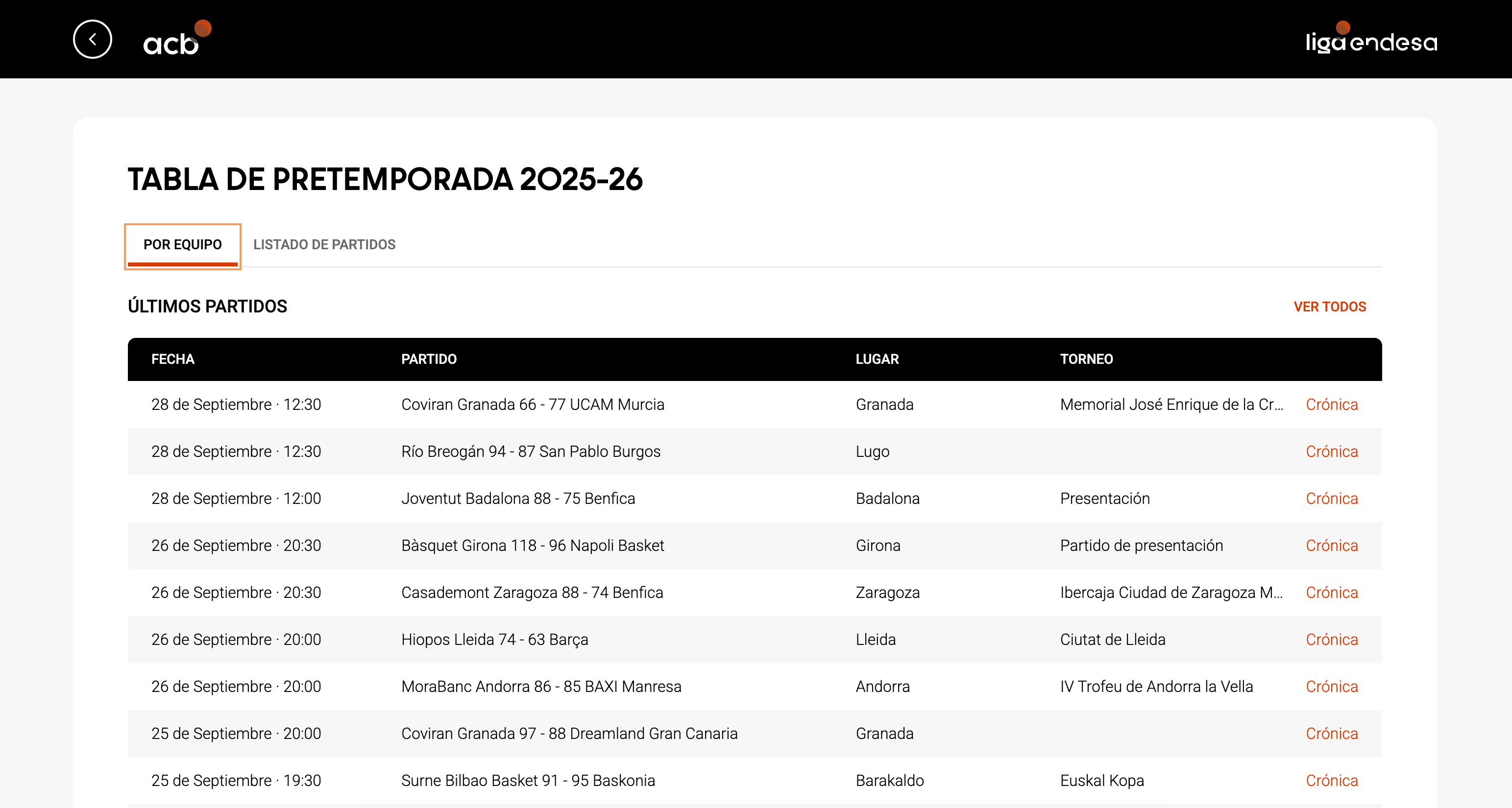
Tenemos que sacar los enlaces de los links donde pone “crónica”. Como siempre, seleccionamos las librerías y tecleamos el siguiente código:
La madre del cordero aquí es la libreria tabulapdf, si no la tienes:
# cualquiera de las dos
install.packages(”tabulapdf”)
# o
install.packages(”tabulapdf”, repos = c(”https://ropensci.r-universe.dev”, “https://cloud.r-project.org”))Una vez que ya tenemos la librería:
library(tidyverse)
library(tabulapdf)
library(rvest)
library(janitor)
links <- “https://acb.com/es/tabla-pretemporada/2025-26” %>%
read_html() %>%
html_elements(”td a”) %>%
html_attr(”href”) Esto nos da una lista de 113 enlaces como esta.

Ahora, una vez que tenemos los enlaces, creamos una función que nos devuelva un dataframe con los enlaces de descarga del archivo (si no hay, veremos NA).
links_fn <- function(links){
df = tibble(
enlaces = links %>%
read_html() %>%
html_element(”[itemprop=’articleBody’] a”)%>%
html_attr(”href”))
return(df)
}
links_df <- map_df(links, links_fn)
Vale, y aquí ya empezamos con las complicaciones: como se ve, hay archivos .pdf y archivos .jpg.
